HyperLake
Command center for composable sovereign agentic infra
Command center for composable sovereign agentic infra
Command center for composable sovereign agentic infra
HyperLake is built for organizations preparing for a world where AI agents become primary users of infrastructure.
Today, most enterprise infrastructure was designed for humans, dashboards, applications, and scheduled pipelines. AI agents behave differently. They query data, call tools, trigger workflows, generate artifacts, operate across systems, and need continuous access to governed compute, data, policies, and services.
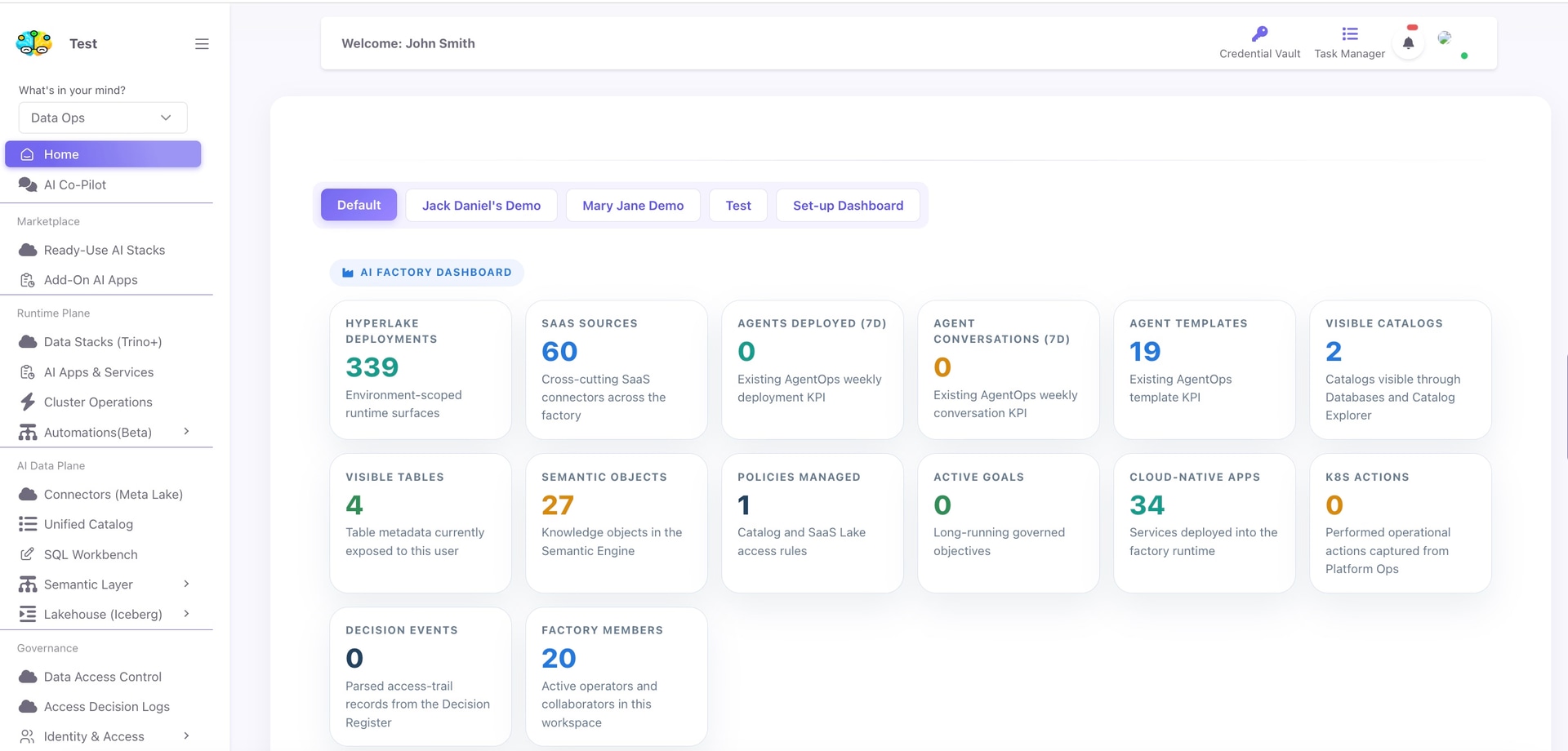
HyperLake provides the command center to deploy, manage, run, secure, and govern that agentic infrastructure. The first product wedge is Agentic Data Cloud Infrastructure: open-stack data, analytics, semantic, workflow, and agent infrastructure deployed inside the customer’s own VPC, private cloud, or on-prem environment.
But the broader vision is larger than one stack. HyperLake is designed to manage many agentic infrastructure stacks: HyperLake-native stacks, customer-owned cloud services, AWS/GCP/Azure-native components, open-source technologies, governed data services, workflow systems, MCP tools, and future production-ready agentic use cases.
The goal is to make agentic infrastructure usable, secure, and production-ready end to end. Enterprises should be able to choose the stack, deploy it where their data lives, govern every human and agent interaction, audit every action, and scale new AI use cases without rebuilding the operating layer each time.
HyperLake is an open lakehouse infrastructure deployed inside your own cloud environment — designed to serve both AI agents and human users with secure, governed access to data at scale. Rather than forcing organizations to move data outside their perimeter, HyperLake deploys a full data and analytics stack within the customer's VPC, private cloud, or on-premises infrastructure. Built on open standards like Apache Iceberg, Trino, and Kafka, it eliminates vendor lock-in and compute markups while providing fine-grained governance, auditability, and AI-ready capabilities.
HyperLake uses Trino for distributed query execution across your data lake, enabling fast, interactive analytics on petabyte-scale datasets without moving data to a separate warehouse.
Iceberg provides reliable, performant table management with schema evolution, partition evolution, time-travel queries, and ACID transactions — all running on your own object storage.
The platform includes vector search, agent APIs, and MCP protocol support, making it straightforward for AI agents to discover, query, and act on governed data without manual intervention.
HyperLake deploys entirely inside your cloud account, with RBAC, audit logging, and data contracts ensuring every human and agent interaction is tracked and controlled.
HyperLake is built for a world where AI agents become primary users of infrastructure — not just an afterthought.
Most enterprise infrastructure was designed for dashboards, scheduled pipelines, and human-operated applications. HyperLake flips that assumption, providing a command center purpose-built to deploy, manage, secure, and govern agentic infrastructure. The platform doesn't just bolt AI capabilities onto existing data stacks — it rethinks the operating layer so that agents can query data, call tools, trigger workflows, and generate artifacts with the same governance and auditability as human users.
Your organization is preparing for production AI agent workloads and needs infrastructure that keeps data sovereign, eliminates compute markups, and provides end-to-end governance across human and agent interactions. HyperLake is especially relevant if you want to avoid vendor lock-in by using open standards (Apache Iceberg, Trino, Kafka) and deploy across AWS, GCP, Azure, OVH, private cloud, or on-premises environments.
Other tools you might consider
Loading comments…
Maker
cerebrixOS
Visit Website
hyperlake.cloud
Project Info
Product Keywords