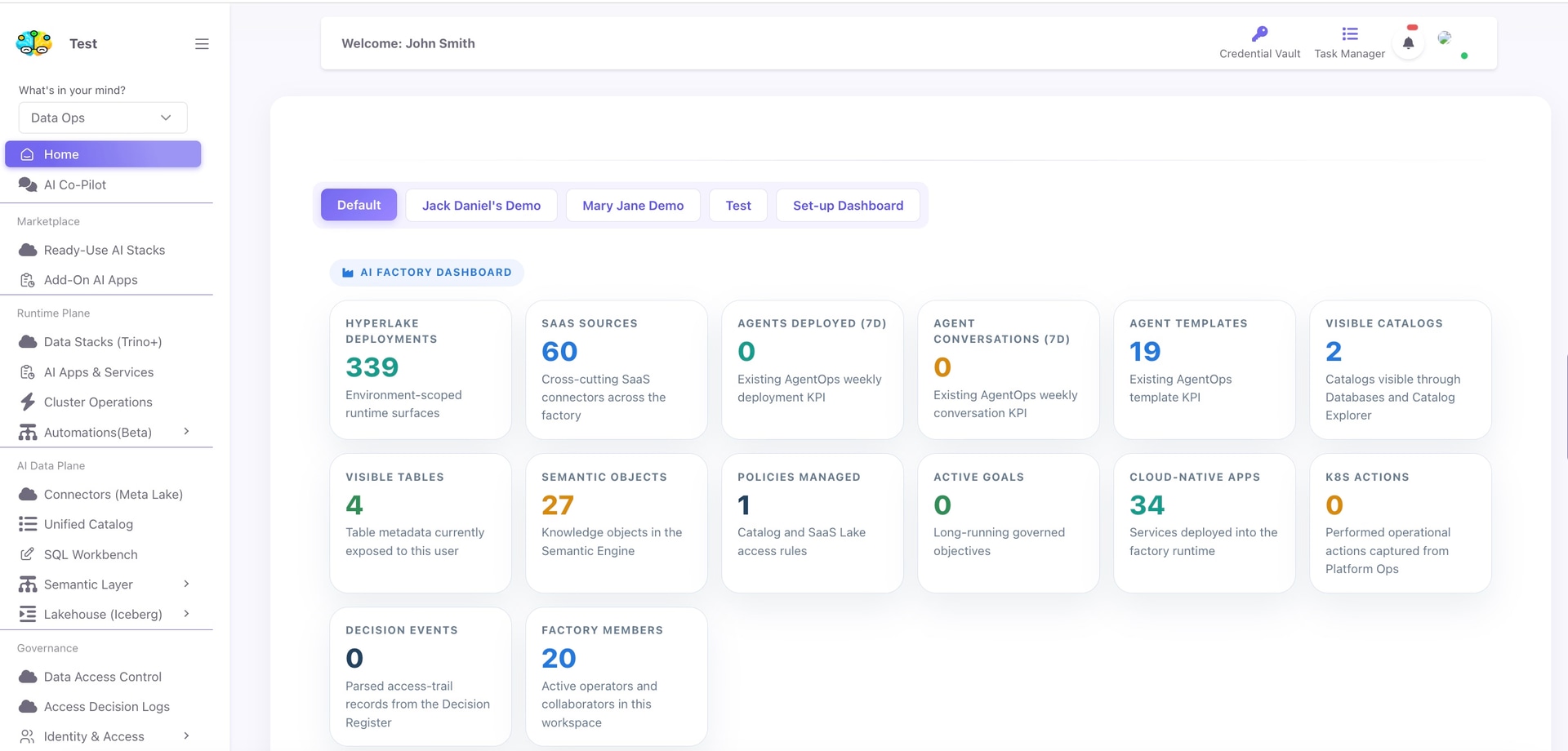
HyperLake 专为那些为 AI 代理成为基础设施主要用户的未来做准备的组织而构建。
如今,大多数企业基础设施都是为人类、仪表盘、应用程序和定时任务管道设计的。AI 代理的行为方式截然不同。它们查询数据、调用工具、触发工作流、生成工件、跨系统操作,并且需要持续访问受治理的计算、数据、策略和服务。
HyperLake 提供了一个指挥中心,用于部署、管理、运行、保护和治理这类代理基础设施。首个产品切入点是无代理数据云基础设施:在客户自己的 VPC、私有云或本地环境中部署的开放栈数据、分析、语义、工作流和代理基础设施。
但更宏大的愿景远不止单一技术栈。HyperLake 旨在管理多种代理基础设施栈:HyperLake 原生栈、客户自有的云服务、AWS/GCP/Azure 原生组件、开源技术、受治理的数据服务、工作流系统、MCP 工具以及未来可投入生产的代理用例。
目标是让代理基础设施从端到端变得可用、安全且可投入生产。企业应能够选择技术栈,将其部署在数据所在的位置,治理每一次人类与代理的交互,审计每一个操作,并在无需每次重建运营层的情况下扩展新的 AI 用例。
HyperLake 是一款部署在您自有云环境中的开放湖仓一体基础设施——旨在为 AI 智能体和人类用户提供安全、受管控的大规模数据访问。它无需将数据迁出组织边界,而是在客户的 VPC、私有云或本地基础设施内部署完整的数据与分析栈。基于 Apache Iceberg、Trino 和 Kafka 等开放标准构建,HyperLake 消除了供应商锁定和计算溢价,同时提供细粒度管控、审计追踪和 AI 就绪能力。
HyperLake 使用 Trino 在数据湖上执行分布式查询,无需将数据迁移至独立数仓即可对 PB 级数据集进行快速交互式分析。
Iceberg 提供可靠、高性能的表管理,支持模式演进、分区演进、时间旅行查询和 ACID 事务——全部运行在您自己的对象存储上。
平台包含向量搜索、智能体 API 和 MCP 协议支持,使 AI 智能体无需人工干预即可发现、查询和操作受管控数据。
HyperLake 完全部署在您的云账户内,通过 RBAC、审计日志和数据合约确保每次人类与智能体交互都被追踪和控制。
HyperLake 专为 AI 智能体成为基础设施主要用户的世界而构建——而非事后补救。
大多数企业基础设施是为仪表盘、定时管道和人工操作应用设计的。HyperLake 颠覆了这一假设,提供了一个专为部署、管理、保护和管控智能体基础设施而建的指挥中心。该平台并非简单地将 AI 能力附加到现有数据栈上,而是重新设计了操作层,使智能体能够以与人类用户相同的管控和审计标准查询数据、调用工具、触发工作流并生成制品。
您的组织正在为生产级 AI 智能体工作负载做准备,需要保持数据主权、消除计算溢价,并为人类与智能体交互提供端到端管控的基础设施。如果您希望通过使用开放标准(Apache Iceberg、Trino、Kafka)避免供应商锁定,并能在 AWS、GCP、Azure、OVH、私有云或本地环境中部署,HyperLake 尤其值得关注。
其他您可能感兴趣的工具
Loading comments…
制作者
cerebrixOS
访问网站
hyperlake.cloud
项目信息
产品关键词